Genauer als GPT-4: Wie CodeReduce von Snyk die Leistung anderer LLMs verbessert hat

7. Mai 2024
0 Min. LesezeitSnyk ist seit der Einführung von Snyk Code im Jahr 2021 ein Pionier im Bereich der KI-gestützten Cybersicherheit. Die KI-Engine DeepCode bietet zum ersten Mal unübertroffene Genauigkeit und Geschwindigkeit bei der Identifizierung von Sicherheitsproblemen im SAST-Bereich. In den letzten 3 Jahren haben wir den Aufstieg von KI und LLMs erlebt, bei dem Snyk mit der Einführung neuer KI-basierter Funktionen wie DeepCode AI Fix, unserer Funktion zum Autofixing von Schwachstellen oder unserer Funktion zur Erreichbarkeit von Drittanbietern eine Vorreiterrolle gespielt hat.
Wir haben kürzlich große Modellverbesserungen in DeepCode AI Fix angekündigt, einer Beta-Funktion, die von Snyk Code identifizierte Security-Fixes automatisch behebt. DeepCode AI Fix kombiniert die neueste KI-Technologie mit den Fähigkeiten von Experten im eigenen Haus, um zuverlässige Fixes zu generieren. Die Behebung von Sicherheitsproblemen ist komplex. Um mehr darüber zu erfahren, wie wir dies tun, werden wir in das Forschungspapier eintauchen, in dem die Hauptzutaten hinter DeepCode AI Fix erläutert werden – die CodeReduce-Technologie und unser kuratierter Security-Fix-Datensatz.
Automatisierung von Security-Fixes – ein komplexes Problem
Entwickler/innen verwenden oft viel Zeit darauf, Security-Fixes selbstständig zu finden und zu beheben. Vor DeepCode AI half Snyk Code den Entwickler/innen im ersten Schritt bei der Identifizierung der Probleme, aber selbst dann konnte der nächste Schritt, das Beheben von Security-Fixes, schwierig und zeitaufwendig sein, weil die Entwickler/innen häufig nicht in Security geschult waren und es immer noch sind. Die Behebung von Sicherheitsproblemen bedeutet, dass Entwickler/innen den Code manuell überprüfen, herausfinden müssen, wie er funktionieren soll, die Sicherheitsprobleme im Kontext des Codes verstehen und dann recherchieren müssen, wie sie behoben werden können, bevor sie das Problem tatsächlich beheben.
Die automatisierte Behebung von Sicherheitsproblemen, das sogenannte Autofixing, steht seit Jahren bei vielen Unternehmen ganz oben auf der Agenda, um den Arbeitsaufwand für die Problembehebung zu reduzieren. Trotz vieler Versuche erwies es sich jedoch als schwierig, eine Lösung mit präzisen Fixes zu entwickeln. Daher konzentrierten sich die meisten Autofixing-Tools auf eine kleine Anzahl von Problemen, triviale Änderungen, die nur wenige Codezeilen betrafen, oder reine Formatierungsprobleme.
Mit dem Aufkommen der LLMs sahen wir das Potenzial, mit der neuen Generation der KI eine bessere Autofixing-Fähigkeit zu entwickeln. Doch selbst LLMs haben Grenzen, wenn es darum geht, Sicherheitsprobleme zu beheben, wenn sie nicht ausreichend auf die gewünschten Ergebnisse eingestellt sind. Die meisten LLMs wurden mit einer Vielzahl von Daten und Programmierungen trainiert, aber nicht speziell für die Behebung von Sicherheitsproblemen. Und das bedeutete für uns zwei Hauptprobleme:
Für etwas so Spezielles wie das Autofixing von Sicherheitsproblemen benötigen LLMs einen speziellen Datensatz mit Security- und semantischen Code-Fixes, aus dem sie lernen können, um relevante und genaue Code-Fixes zu produzieren.
Halluzinationen und die Fähigkeit von LLMs, jedes Mal, wenn sie eine Ausgabe erzeugen, einen begrenzten Kontext zu verarbeiten, bedeuten, dass das Hinzufügen von mehr Code zu Prompts, um ein Universal-LLM (im Gegensatz zu einem speziell für Sicherheit trainierten) zu genaueren Ausgaben zu führen, nicht immer bessere Ergebnisse liefert.
Die Einschränkungen von LLMs angehen, um bessere Fixes zu produzieren
Wir haben beschlossen, dass die Vorteile der Verwendung von LLMs den Arbeitsaufwand für die Behebung der identifizierten Probleme überwiegen, also haben wir es selbst in die Hand genommen, diese zu lösen.
Fix-Datensatz
Um die bestmöglichen Ergebnisse zu erzielen, haben wir einen umfassenden Datensatz von Open Source Security-Fixes erstellt. Zunächst haben wir ein umfassendes Labeling von Open Source Commits durchgeführt und einen sauberen Datensatz mit Problemen und Fixes für JavaScript erstellt (inzwischen haben wir dasselbe mit anderen Sprachen wie Java, Python, C/C++, C#, Go und APEX getan). Zweitens haben wir, anstatt manuell weitere gelabelte Daten hinzuzufügen, die Programmanalysefunktionen von Snyk Code aus unserer DeepCode AI Engine genutzt, um effizient denselben quantitativen Effekt wie bei der Erstellung von Label-Daten zu erzielen und saubere Datensätze zu erstellen.
CodeReduce-Technologie (zum Patent angemeldet)
CodeReduce nutzt die Programmanalyse, um den Aufmerksamkeitsmechanismus des LLM auf die Teile des Codes zu beschränken, die für die Durchführung des Fixes erforderlich sind, indem der LLM auf einen kürzeren Snippet des Codes fokussiert wird, der den gemeldeten Fehler und den notwendigen Kontext enthält. Dadurch wird die Menge an Code, die das LLM verarbeiten muss, drastisch reduziert, was wiederum dazu beiträgt, die Qualität der Fixes bei allen getesteten KI-Modellen zu verbessern und Halluzinationen zu reduzieren. Außerdem werden weniger Informationen durch das Modell geleitet, was die Verarbeitung beschleunigt. Es ermöglicht die Generierung von Fixes in Echtzeit, sodass Sie nicht nur genauere und relevantere Fixes erhalten, sondern auch schnellere Fixes.
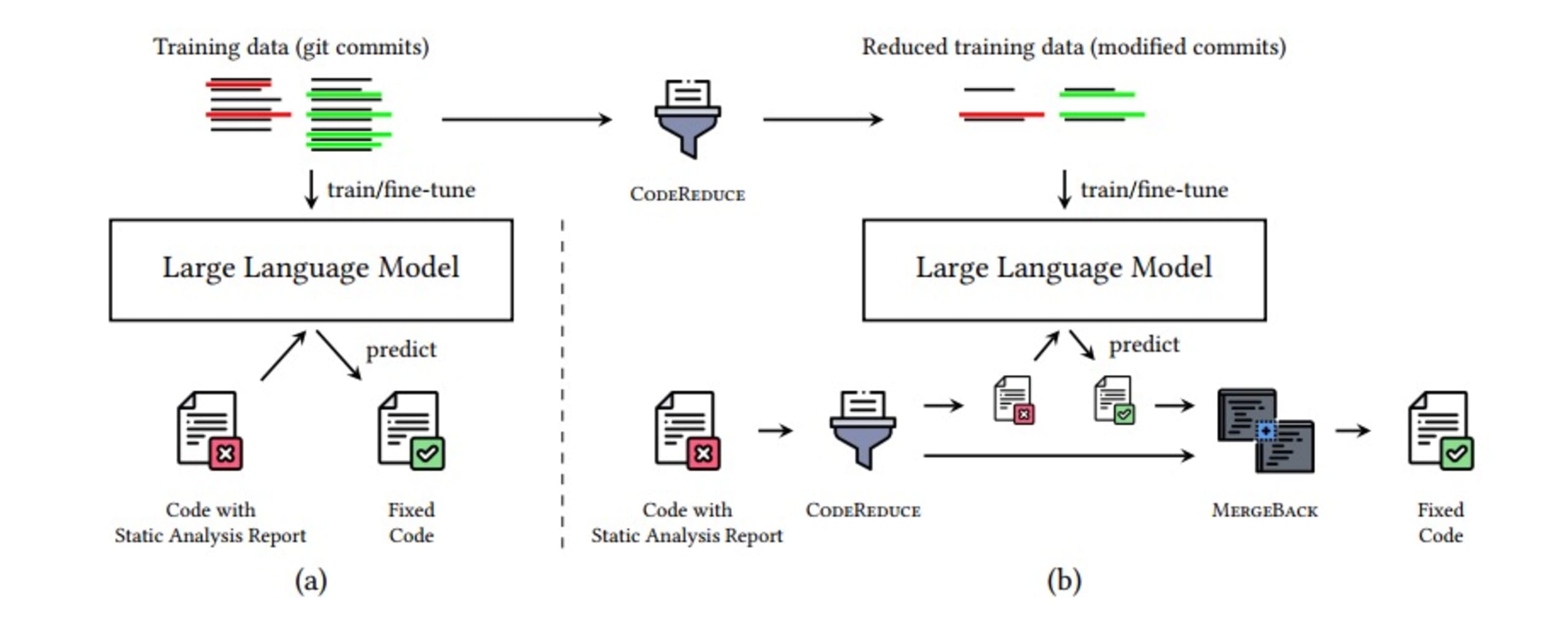
Der Prozess für CodeReduce umfasst die folgenden Schritte:
Identifizieren Sie das Sicherheitsproblem
CodeReduce auf den minimal erforderlichen Code mit Kontext
Fügen Sie den CodeReduced Code zum LLM-Prompt hinzu und generieren Sie einen Fixes
Anwenden des Fixes
Verwenden Sie die Scan-Funktionen von Snyk Code, um erneut zu überprüfen, ob der DeepCode AI Fix die Schwachstelle behoben hat und ob durch den/die Fixes keine neuen Schwachstellen eingeführt worden sind
MergeBack des Fixes in den ursprünglichen Code
Die folgende Abbildung zeigt, wie die Pipeline für die automatische Behebung von Sicherheitsproblemen aussieht. Dank zusätzlicher Optimierungen, die Sie in dem Forschungspapier über CodeReduce nachlesen können, geschieht dies alles in wenigen Sekunden.
Was sind die Ergebnisse?
Nachdem diese Probleme gelöst waren, mussten wir testen, wie gut unsere automatischen Security-Fixes funktionierten, also haben wir einen Benchmark erstellt, der für verschiedene LLMs verwendet werden kann.
Wir haben unsere Bewertungen mit den Metriken „Pass@𝑘“ und „ExactMatch@𝑘“ für Modelle, die CodeReduce verwenden (in der Tabelle unten mit dem Symbol ‡ gekennzeichnet), gegen die Grundlinien von TFix, einem fensterbasierten Modell, und verschiedenen Modellen mit großem Kontext, wie GPT-3.5 und GPT-4, durchgeführt.
Die Variable „k“ in „Pass@k“ misst, wie viele (von mindestens einem Fix bis zu allen 5 Fixes) der 5 Fixes, die jedes Mal generiert werden, das relevante Sicherheitsproblem beheben und keine neuen Sicherheitsprobleme einführen.
Wir haben außerdem 5 Kategorien von Sicherheitsproblemen definiert, gegen die getestet werden soll:
AST: Schwachstellen, die einen abstrakten Syntaxbaum, aber keinen speziellen Datenfluss erfordern
Lokal: Falsche Werte, die in Methoden fließen, die sie nicht akzeptieren würden
FileWide: Signaturen oder Implementierungsprobleme
SecurityLocal: API-Nutzung, Verfolgung von Methodenaufrufen
SecurityFlow: Komplexe Taint-Analyse, die einen komplexen Datenfluss erfordert
Wir haben auch verschiedene LLMs – StarCoder, Mixtral, T5, GPT-3.5 und GPT-4 – zum Vergleich ausgewählt. Die Ergebnisse waren wie folgt:
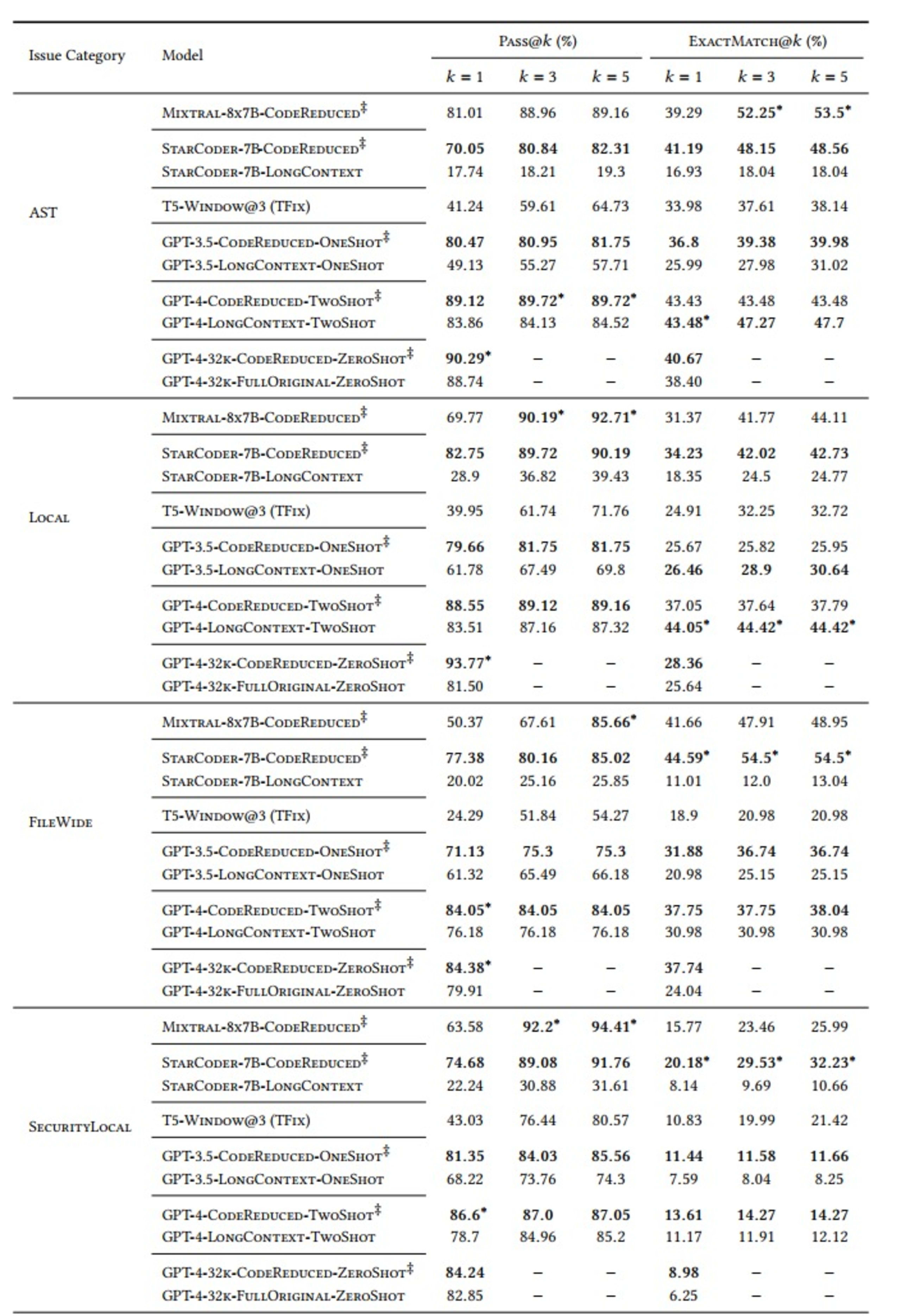
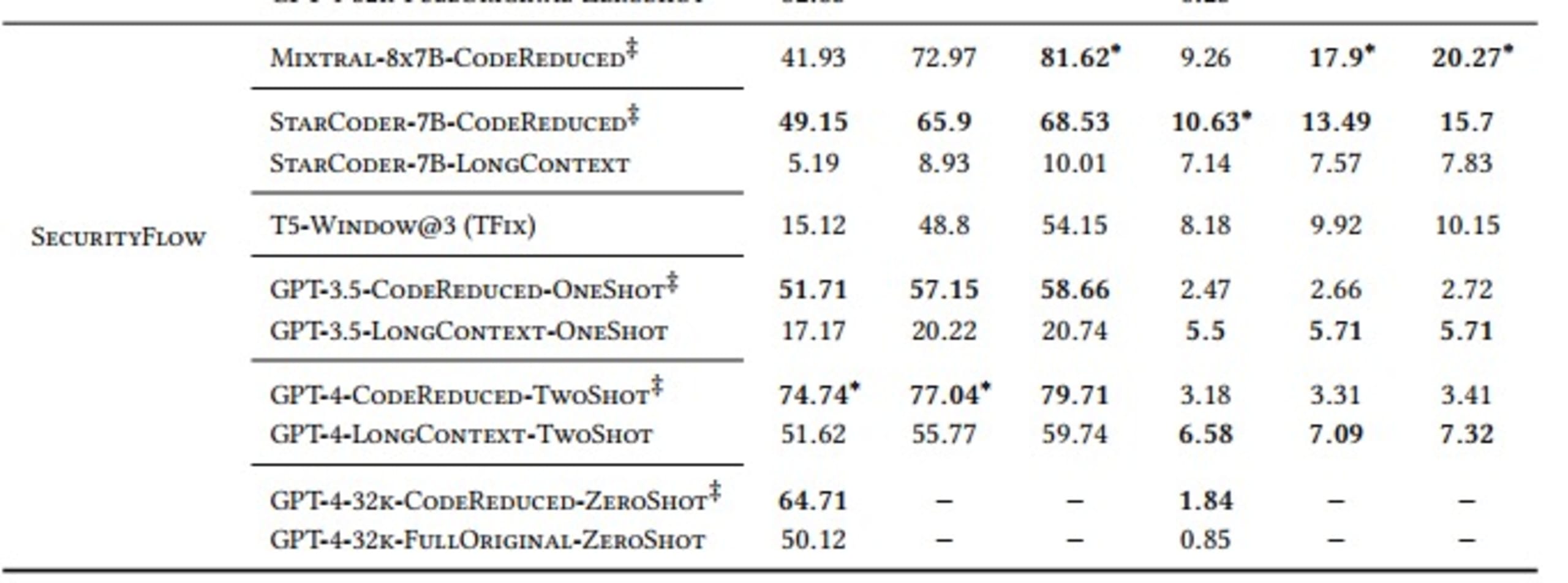
Wie die Tabelle zeigt, schneiden Modelle, die normalerweise die komplexen, weitreichenden Abhängigkeiten erlernen, die für die Erstellung eines korrekten Fixes erforderlich sind, bei Verwendung des von CodeReduce extrahierten Codekontextes deutlich besser ab als bei der Erstellung von Fixes ohne die Hilfe von CodeReduce. Ein gutes Beispiel dafür ist die enorme Verbesserung des Pass@5-Ergebnisses für die Behebung von AST-Problemen bei Verwendung des StarCoder-Modells. Die Erfolgsquote stieg von 19,3 % (ohne CodeReduce) auf 82,31 % (mit CodeReduce).
Kernergebnisse im Fokus
Insgesamt übertraf DeepCode AI Fix die bisherige State-of-the-Art-Baseline von TFix und verhalf mehreren beliebten KI-Modellen in verschiedenen Setups zu einer besseren Leistung. Das liegt daran, dass DeepCode AI Fix die Programmanalyse durch die von Snyk entwickelte CodeReduce Technologie nutzt, um mit weitreichenden Abhängigkeiten und Datenflüssen umzugehen. Auf diese Weise vereinfacht DeepCode AI Fix seine Aufgabe, die relevanten Sicherheitsprobleme zu erkennen, indem es den Fokus seiner Aufmerksamkeit einschränkt, was zu präziseren, relevanten Fixes führt.
Sie können die leistungsstarke Funktionalität von DeepCode AI Fix jetzt in der IDE erleben, indem Sie sich für Snyk Code registrieren und die „Snyk Code Fix Vorschläge“ in den Einstellungen der Snyk Vorschau aktivieren. Weitere Informationen finden Sie in unserer Dokumentation, und Sie können die Zukunft von DeepCode AI Fix mitgestalten, indem Sie Benutzer-Feedback zu unseren Fixes in Snyk Code geben.
Beginnen Sie mit Capture the Flag
Lernen Sie, wie Sie Capture the Flag-Herausforderungen lösen, indem Sie sich unseren virtuellen 101-Workshop auf Abruf ansehen.